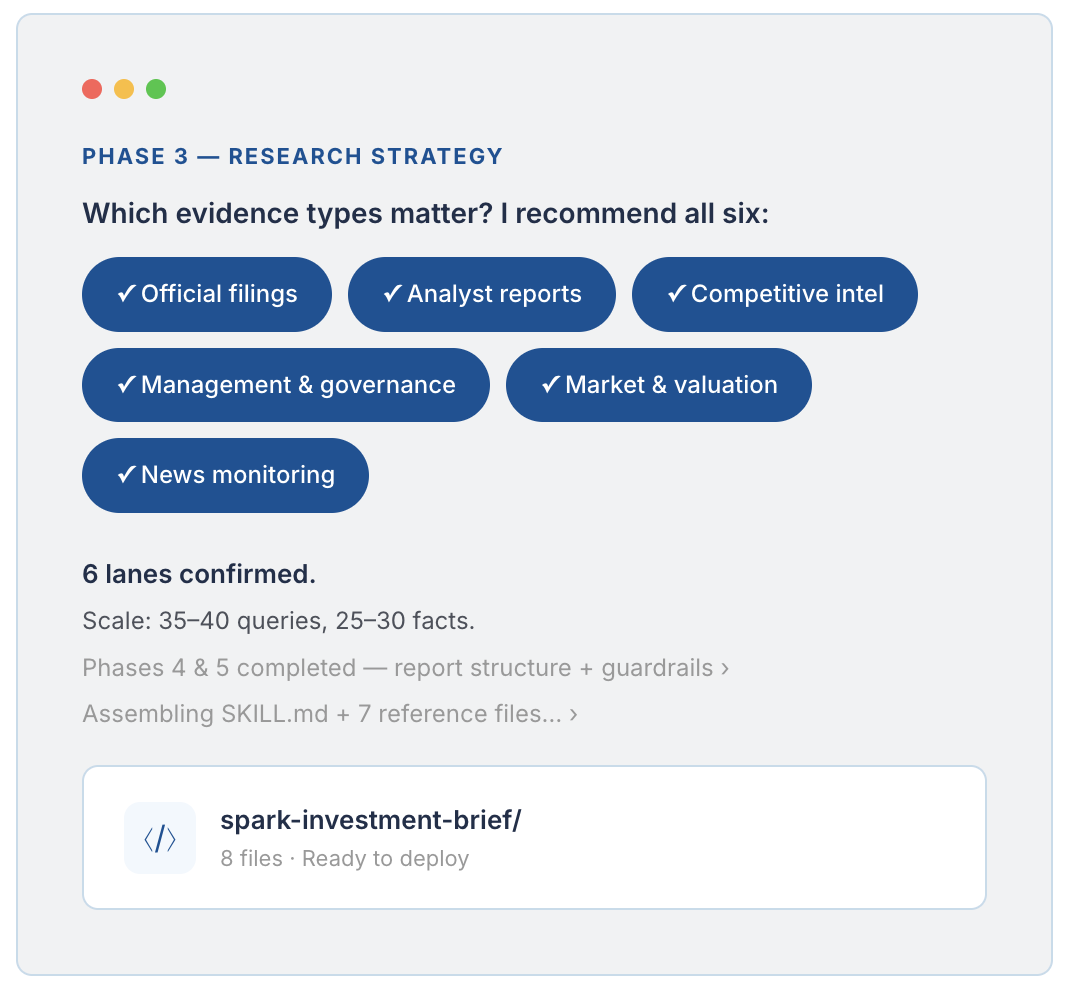
No code needed. Just describe the research domain you care about, and SPARK builds a custom recipe through a short guided conversation. Within minutes, you have a repeatable, verified research workflow tailored to your exact questions.

Reviewers and leadership start asking where each claim came from before signing off, whether it's a deck, a memo, or a board paper. The courts already require it: dozens of federal judges now make lawyers certify that AI output was checked, after a run of fabricated-case scandals. Boardrooms are next, and the teams logging provenance now will set the standard everyone else retrofits to.

Teams start reporting trust and coverage the way they report budget, spend, or any other quality metric. "How verified is the intelligence we're acting on?" becomes a standing line in the business review rather than an afterthought, with a number attached.

It stops being something people remember to check and becomes something the pipeline enforces. From dashboards to automated reports to personalisation engines, an unscored claim simply doesn't make it into the decision. The check moves from habit to infrastructure.
![[Placeholder] AI will write the research, but it won't tell you which parts to believe.](https://landing.aicadium.ai/hs-fs/hubfs/use-cases-header.jpg?width=400&height=200&name=use-cases-header.jpg)
The anchor essay behind this briefing: the shift, the framework, and the field evidence, gathered into one read.
![[Placeholder] Watch a SPARK scan run from prompt to scored report](https://landing.aicadium.ai/hs-fs/hubfs/3%20Strategy%20Roadmap.png?width=400&height=200&name=3%20Strategy%20Roadmap.png)
A short walkthrough of a live run, from a single trigger phrase to a report where every claim is sourced.
![[Placeholder] Ground Truth, Episode 02: Building SPARK](https://landing.aicadium.ai/hs-fs/hubfs/AI-enabled%20vs%20AI-first%20vs%20AI-native%20-%20How%20do%20you%20know%20which%20strategy%20to%20choose%3F.png?width=400&height=200&name=AI-enabled%20vs%20AI-first%20vs%20AI-native%20-%20How%20do%20you%20know%20which%20strategy%20to%20choose%3F.png)
The story of building SPARK: when it first clicked, what fought back, and the one thing we are still not sure we can solve.